手元の捨てようにも捨てきれなかった書籍を電子化することにした。今までペーパーや雑誌の記事をスキャンしたことはあったが、書籍を丸ごと電子化する作業は初めてやった。
自炊するには裁断機や両面スキャン可能なスキャナーなどふさわしい道具を揃えるべきだが、とりあえず今のところはカッターと普通のA4スキャナーを使っている。
ページののり付けを剥がす
- 表紙を剥がす
- ページを数ページずつ剥がす
- 浮き出てきたのり付け部分をカッターで削る
- 2と3を繰り返す
という流れでかなり地道な作業をしている。ページが数百ページにも及ぶと手が疲れてきて大変な労力を使った気になる。
EPSON Scanを使った自炊のコツ・ファイルサイズ削減
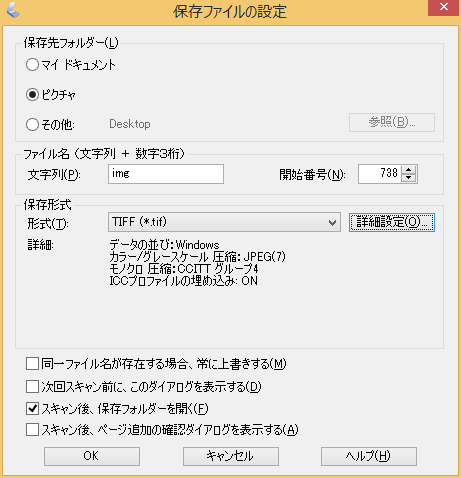
原稿種は「雑誌」、解像度は「300dpi」に設定する。原稿に写真が多数あれば「モアレ除去」にチェックを入れる。2色刷の原稿なら「文字くっきり」にチェックを入れるか明るさ調整でコントラストを強めて、画像ファイルの色数を減らすようにする。モノクロ原稿の場合は取り込む形式をTIF(CCITT G4圧縮)に設定する。JPEGだとモノクロ原稿でもかなりサイズを食う。
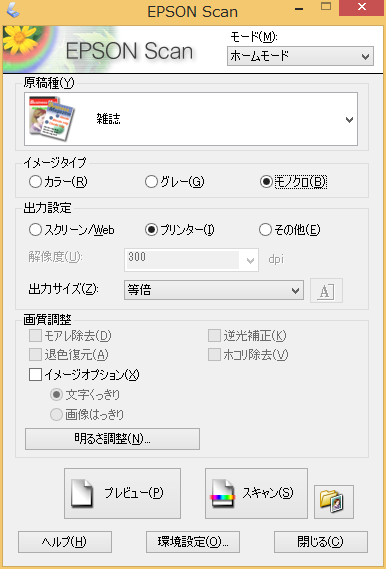
スキャンはページの開く側をスキャナーの端に揃え、裏面をスキャンするときは縦方向に上下をひっくり返して両面をスキャンしていく。
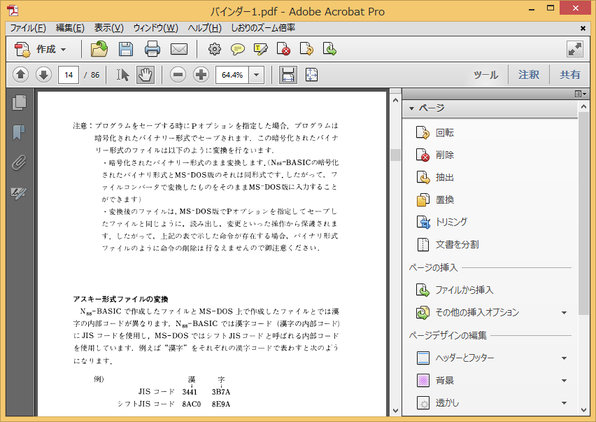
Adobe AcrobatでPDF化
「作成」→「ファイルを単一のPDFに結合」でページをまとめる。奇数または偶数ページで180度回転を行ってからOCR処理にかける。
必要に応じてしおりに目次を作成する。しおりに項目を追加するとページのジャンプ先と表示倍率が保存される。既定だとしおりにジャンプしたときにしおり作成時の表示倍率に変わってしまう。しおりジャンプ時に表示倍率を維持したい場合は、しおりのプロパティから「アクション」タブで「倍率」を「ズーム設定維持」に設定しておく必要がある。
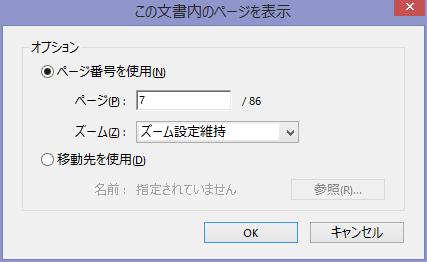
しおりの表示倍率を一括で設定するプラグインがあるので、これを活用するといい。
- Adobe Acrobat しおりのズーム設定を一括で行うプラグイン
- SetZoomRatioOfBookmarks.api
取り込んだスキャン画像をテキスト検索できればいいという程度ならAcrobatのテキスト認識機能で十分 。一応縦書きの文章も認識できるが、ルビがふってあると誤認識の原因になる。テキストを完全にデジタルデータ化したいなら、構文・辞書解析機能が優れている日本語OCRソフトを使った方がいい。
現在販売されている日本語OCRソフトは読取革命のみ。現行のバージョンはルビの認識には対応していないらしい。
 |
Adobe Acrobat 11 Standard Windows版 |
| クリエーター情報なし | |
| アドビシステムズ | |
 |
パナソニック 読取革命Ver.15 製品版 |
| クリエーター情報なし | |
| パナソニック |